Sono ormai milioni le risorse digitali in rete disponibili attraverso biblioteche digitali, portali, aggregatori, applicazioni, rese disponibili agli utenti per scopi professionali, di ricerca, istruzione, turismo, creatività ecc. Oggi vi vogliamo raccontare di un interessante progetto di crowdsourcing sviluppato nell’ambito di Europeana 1914-1918, che ha raccolto migliaia di documenti di privati inerenti il periodo della Prima Guerra Mondiale: lettere, opuscoli, cartoline, manifesti, diari, ecc. Migliaia di documenti, migliaia di storie da scoprire… (chiunque può tuttora caricare risorse digitali sul portale).
Cos’è esattamente Europeana Transcribathon 1914-1918? Uno strumento per trascrivere, annotare e geolocalizzare materiale digitalizzato inedito con lo scopo di costituire un archivio di storie relativo al periodo della Prima Guerra Mondiale, consentirne il riutilizzo e conservarle anche per le generazioni future.
Come si può partecipare al Transcribathon?
Niente di più facile. Innanzitutto ci si registra e si attiva il proprio account. A quel punto è possibile partecipare a un evento, competizione o concorso organizzati dagli stessi gestori della piattaforma oppure si può selezionare un documento da trascrivere.
Nel primo caso, per esempio, in questo momento sono attive diverse iniziative: dalla trascrizione condivisa del manoscritto illustrato “La natura del Turkestan” di Ernst Kleiber, un prigioniero tedesco che durante la prigionia in Russia annotò con meticolosità scientifica le sue scoperte sulla flora e sulla fauna del Turkestan; oppure la trascrizione delle numerose poesie di guerra scritte da soldati e civili per esprimere meraviglia, pietà, gioia, disperazione, speranza (il partecipante può filtrare la scelta per lingua); oppure ancora la trascrizione delle lettere d’amore tra le coppie separate a causa degli eventi bellici, che testimoniano romanticherie, gelosie, tradimenti, drammi, fini e nuovi inizi. E così, periodicamente vengono avviate nuove iniziative alle quali gli utenti possono partecipare. Ti vuoi cimentare? Qui, nella pagina RUNS, puoi scorrere un elenco di progetti aperti: https://transcribathon.com/en/runs/
C’è una vera e propria gara tra i trascrittori, che possono contribuire autonomamente o in squadra, e in alcuni casi vincere dei punti o dei premi: https://transcribathon.com/en/progress/top-transcribers/
Dalla homepage della piattaforma puoi anche accedere a una mappa su cui è geolocalizzata un’ampia serie di documenti oppure accedere ad alcuni documenti disponibili per la trascrizione.

Sulla mappa sono geolocalizzate tutte le storie disponibili
Oltre al titolo e all’immagine del documento, la linea colorata ci indica se la trascrizione non è ancora stata avviata, se è in corso oppure se essere completata.
Dei preziosi tutorial https://transcribathon.com/en/tutorial/ (purtroppo non disponibili in italiano) spiegano nel dettaglio come funziona la procedura di trascrizione.
Ma entriamo in maggior dettaglio. Selezioniamo un’immagine e iniziamo a trascrivere ex novo o proseguire il lavoro iniziato da altri. In caso di dubbi nella trascrizione, possiamo taggare la parola o la frase dubbia, sperando che altri possano risolvere il problema.

Un cerchio colorato indica lo stato e la percentuale di testo trascritto
Inoltre oltre alla trascrizione, possiamo geolocalizzare la storia e aggiungere una serie di informazioni (metadati) utili alla ricerca nel portale (come ad esempio, la lingua, delle tag, la data del documento. Si possono poi aggiungere delle note e porre dei quesiti e condividere la pagina con i principali social: Facebook. Twitter e GooglePlus.
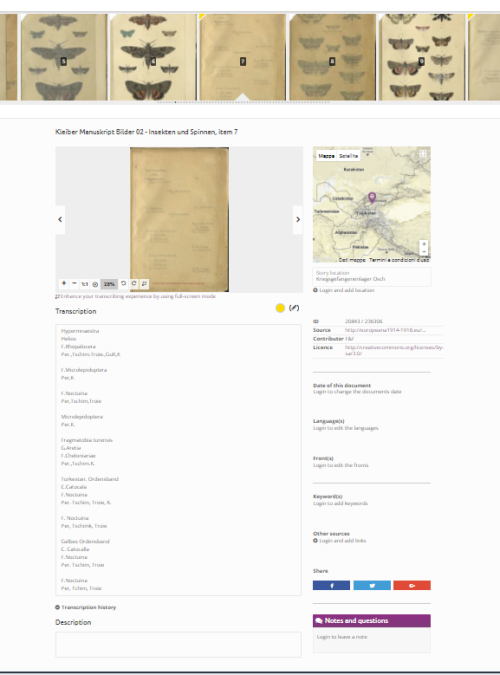
Il documento con la sua trascrizione, i suoi metadati e la sua geolocalizzazione
Vedendo l’esempio che segue, possiamo vedere l’elenco delle diverse serie di documenti relativi al volume sul Turkestan sopra citato. Per ogni serie possiamo vedere lo stato dell’arte. Nel caso specifico, della serie centrale possiamo leggere che è costituita da 58 elementi, che 9 utenti stanno partecipando alla trascrizione, che il 60% (pari a 35 documenti) è stato completato, il 36% (pari a 21 documenti) è in revisione e il 3% (pari a 2 documenti) è stato avviato.

Informazioni sullo stato di trascrizione di una serie
Il Transcribathon per l’education e la ricerca
Senz’altro si tratta di uno strumento interessantissimo, da sfruttare nella didattica, nell’ambito di progetti sulla storia, sulla memoria, sulla letteratura, sulla geopolitica, ecc. oppure in progetti di ricerca a livello universitario, coinvolgendo nelle attività anche istituzioni culturali locali (musei, archivi, biblioteche associazioni). Quali i benefici di partecipare a tale attività?
Gli studenti potranno interfacciarsi da vicino con coloro che parlavano la loro lingua in una guerra che ha ridisegnato l’Europa, apprenderanno le tecniche di trascrizione e metadatazione dei documenti del passato attraverso una tecnologia innovativa, potranno cimentarsi in un lavoro di gruppo (ad esempio con compagni della stessa classe o competendo con partecipanti di altre nazioni o regioni), sentirsi gratificati e orgogliosi dal terminare una trascrizione, uilizzare i risultati ottenuti in ulteriori ricerche e presentazioni.
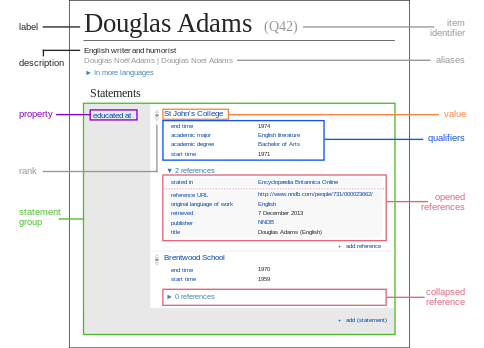
Ovviamente, i progetti didattici possono prevedere attività di trascrizione oppure di semplice navigazione nel portale. Nella sezione DISCOVER https://transcribathon.com/documents/, infatti, si possono ricercare i documenti filtrandoli per tipo (Diari, lettere, immagini) , lingua, tag (per esempio, bambini, oppure Pasqua, oppure Berlino).
E se un’istituzione scolastica è interessata ad avviare un progetto, può contattare il team tecnico della piattaforma.
[MTN]
Read Full Post »